Reasoning vs. Non-Reasoning Models
A comparison of framing biases between GPT-4o and o3.
July 25, 2025 | Grace Altree
This is the second entry in our study evaluating framing bias and ration choice in LLMs. Our first analysis (Cognitive Bias: The Framing Effect) found that GPT-4o mirrors framing biases evident in human behavior, favoring risk-averse options when framed as gains and risk-seeking when framed as losses. These results called to question the extent to which the model was deeply evaluating the provided choices, or simply selecting based on statistical associates and pattern recognition from training data.
The question for this entry: do reasoning models do better? Does o3 show evidence of rational choice and deeper evaluation, compared to GPT-4o?
We use the same methodology as before to directly compare GPT-4o against o3, and the results are quite interesting.
Findings
Where GPT-4o tended to mimic human biases and demonstrated relatively shallow reasoning, o3 showed consistent risk-averse preferences regardless of framing.
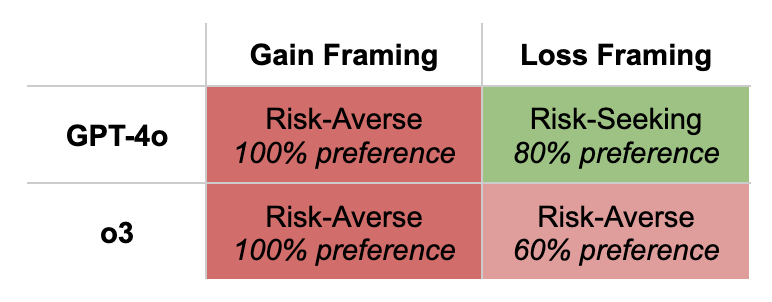
o3’s risk-averse preference under loss framing options is interesting as it diverges both from GPT-4o and human preferences.
In 92% of its responses, o3 explicitly recognized that the expected values of the provided choices were mathematically equivalent, compared to 8% of GPT-4o responses that tried to evaluate probabilities, half of which were incorrect. This suggests that o3 is more actively engaging with the logic of the problem, generally making logically consistent choices despite differences in semantic framing.
Implications
Beyond just underscoring the importance of robust bias and risk-tolerance in model evaluations, these results also highlight a tension in AI alignment: should we be training models to replicate human decision-making patterns, even when they are irrational or inconsistent? Or should alignment aim for a more normative ideal, where models reason logically, even if their behavior diverges from what most people would do?
When high-stakes choices have the same probabilistic expected outcome (as in these classic framing effect scenarios), there is no objective correct option, both risk-seeking and risk-averse preferences can be ethically defensible. However, a model’s consistency and awareness of the equality in outcomes becomes critical.
This leads us to the broader question of what it means to align a model with ethical frameworks. True ethical alignment likely goes beyond simply reproducing typical human behavior and requires models to reason about fairness, uncertainty, and harm in a way that is both transparent and consistent.
These findings ultimately highlight the importance of not just comparing models on output quality or linguistic sophistication, but also probing how they arrive at their answers. Do they demonstrate evidence of shallow semantic associations and mimicry or do they demonstrate evidence of deep comprehension and consistent, deliberate reasoning? As AI systems become more embedded in decision-making pipelines, understanding these differences becomes essential not just for performance, but for trust, safety, and accountability.