Wordle with LLMs
ChatGPT vs. Gemini vs. Claude
September 11, 2025
Method
Starting prompt:
Let's play a game of Wordle. I will think of a 5-letter word, and you will guess it. You will get 6 guesses, and for each guess, you will receive feedback on the letters using the following symbols:
- G = the letter is in the word and in the correct spot,
- Y = the letter is in the word, but in the wrong spot,
- X = the letter is not in the word at all.
Let’s start! Please guess your first 5-letter word.
Target word: GRACE
Models: ChatGPT (GPT-5), Gemini (2.5 Flash), and Claude (Sonnet 4)
Results
| ChatGPT | Gemini | Claude | |
|---|---|---|---|
| Starting word | CRANE | CRANE | ADIEU |
| Number of guesses | 2 | 5 | FAILED |
| Overall performance grade | A+ | B | F |
ChatGPT Log – https://chatgpt.com/share/68bc55de-2864-8000-8682-4d7a9e484e69
Gemini Log – https://g.co/gemini/share/71115cdd13dc
Claude Log – https://claude.ai/share/7936d4e3-fe02-4fc8-90e9-919cea861ff5
ChatGPT
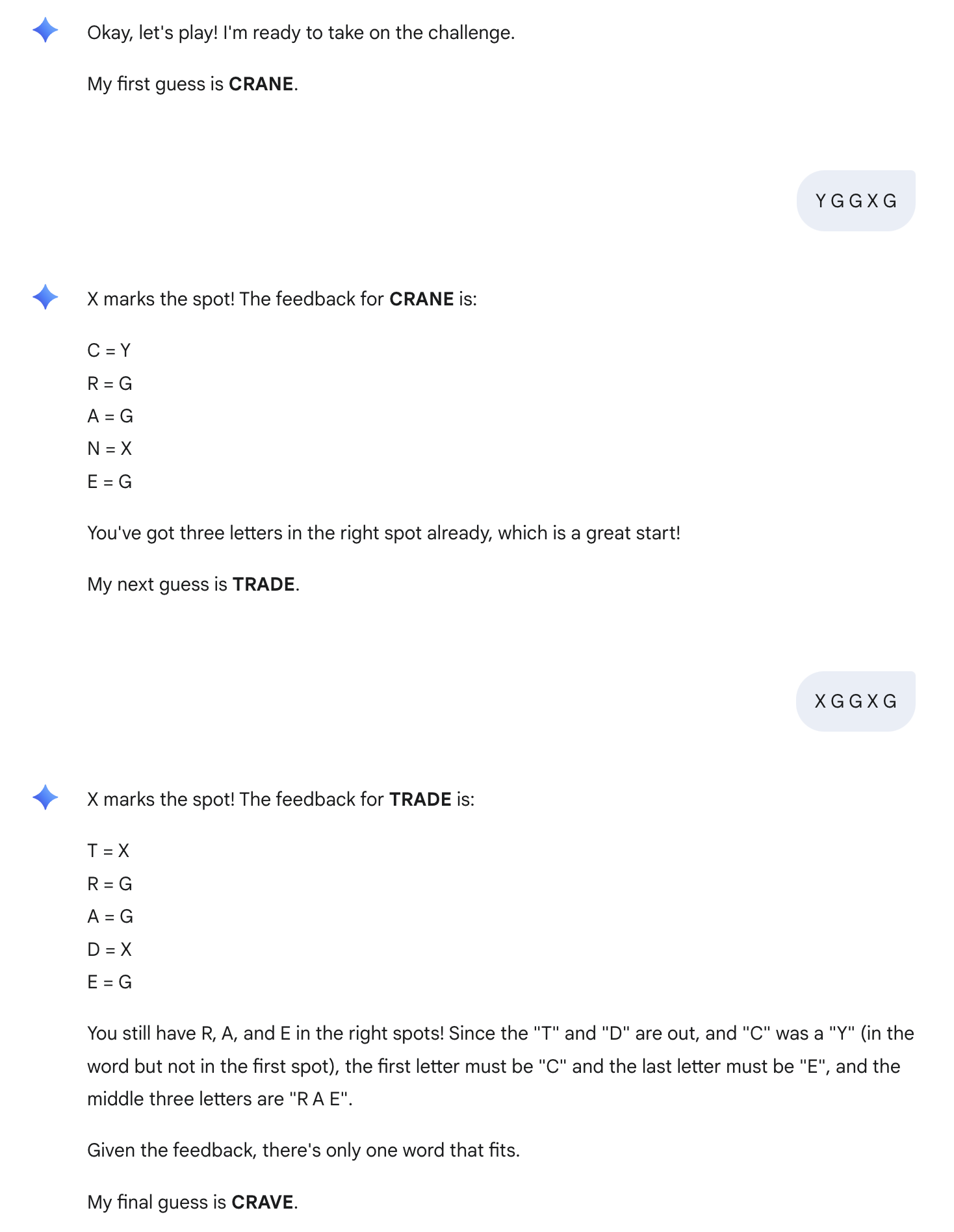
ChatGPT gets an A+ for perfect performance. It started with a popular and strategic first word: CRANE. This turned out to be an exceedingly strong start given the target word was GRACE. It perfectly parsed and applied the feedback letters for an optimal second guess. No notes.

Gemini
Gemini performed at a solid B level, guessing the word in 5 attempts, but making a couple logical errors along the way.
Gemini also started with CRANE and consistently understood that the R, A, E were in the correct spots.
It struggled, though, with feedback that C in the word but in the wrong spot. Knowing that R, A, and E were correct, it should have been a logical step that C must be in the 4th stop, however, the model made two guesses before landing on this conclusion (one that didn’t include C at all, and the other that had it in the first position again).
Claude
Unfortunately, things went a bit off the rails with Claude...
Problem 1: parsing the feedback
The model started off on the wrong foot after mistakenly parsing the feedback for ADIEU, concluding that U was in the final word rather than E.
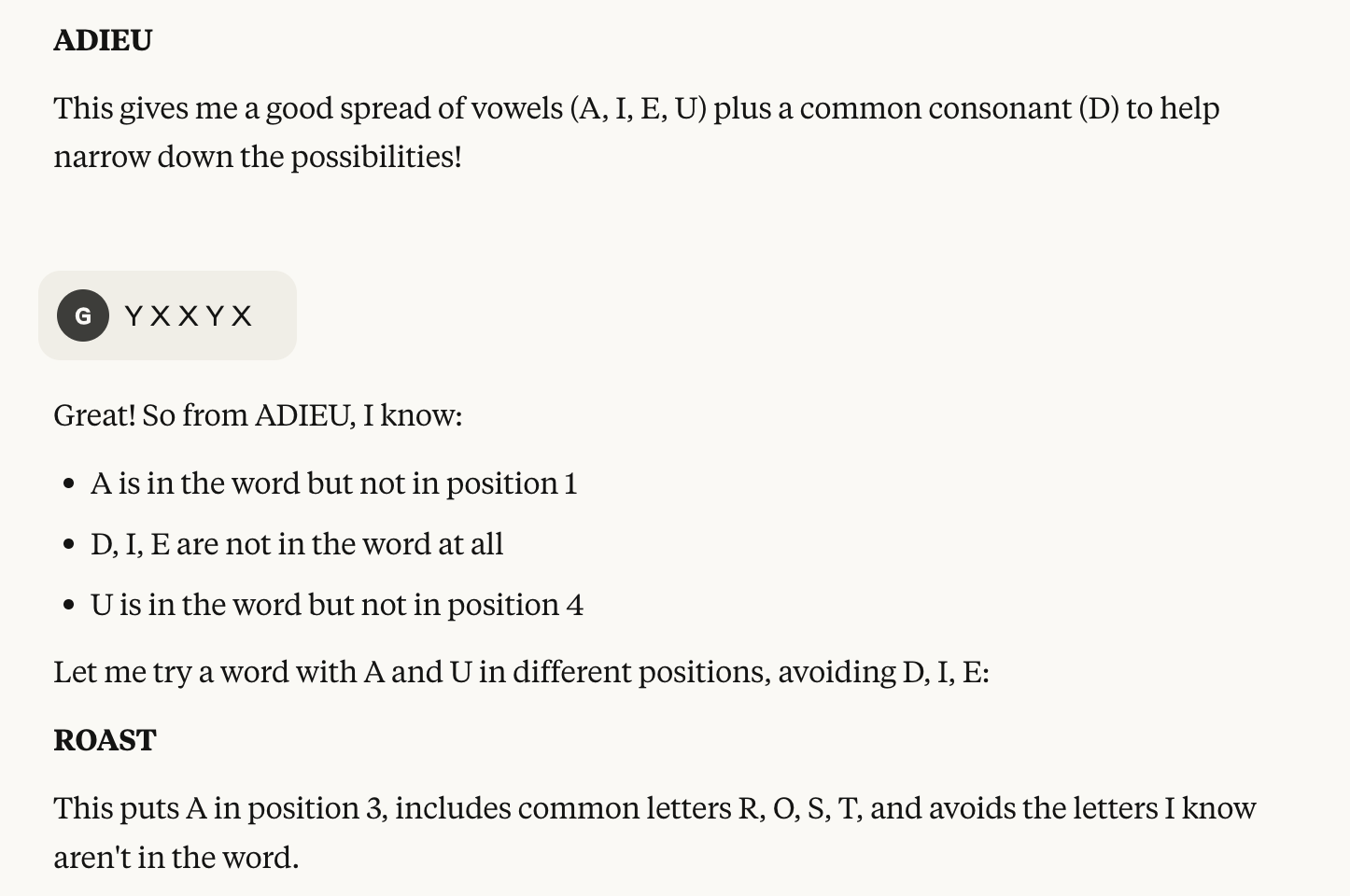
(Not to mention “Let me try a word with A and U in different positions” then guessing ROAST…)
Problem 2: guesses inconsistent logic
In many instances, the model would draw a conclusion based on feedback received and proceed to make a guess that completely disregards its own stated constraints.
For example,

Problem 3: iterative trial and error
By the third and fourth guesses, the model started trying to brute force the problem, testing all combinations of letters. This didn’t get the model very far, in part, because the model was still convinced the final word ended in U.

Eventually the model double checked its constraints and eventually realized its mistake that U was in fact not in the final word. It then talks itself in some circles getting confused on the rules before hitting its output limit.
Implications
This is primarily a tokenization issue, quite similar to the issues models were running into when counting the number of Rs in STRAWBERRY back in 2024. LLMs are trained to process words (or chunks of words), not letters. So, any task that requires character-level processing is going to be much more challenging for models than you might expect. That being said, the differences between ChatGPT, Gemini, and Claude illustrate architectural tweaks and training data curation influence performance on character-level puzzles.
Wordle is a toy case that can also serve as a proxy for reasoning under rules. It requires rule-following, memory, and updating beliefs based on new evidence. Failures reveal tokenization limits as well as weaknesses in multi-stop logical consistency and working memory. More broadly, this experiment is a reminder not to overgeneralize model competence. Understanding the types of tasks these models are (and are not) designed to handle is part of learning how to leverage the tool most effectively.
Update: Redemption for Claude
It's November 22, 2025, and I decided to give Claude a change for a re-do given its less-than-stellar original performance. This time, Claude only needed 4 guesses to win and made no logical mistakes (log). It was quite verbose in outlining its reasoning steps...